Baseweight Canvas
A Desktop Multimodal Application that allows developers to talk with their images and audio. Unlike ollama and other LLM runners, we put vision and audio first.
Pre-release Software
This is a pre-release version (v0.1.0-rc0). Expect bugs and incomplete features. Use at your own risk and please report any issues you encounter.
Features
Vision and Audio First
Built from the ground up for developers who work with visual and audio content.
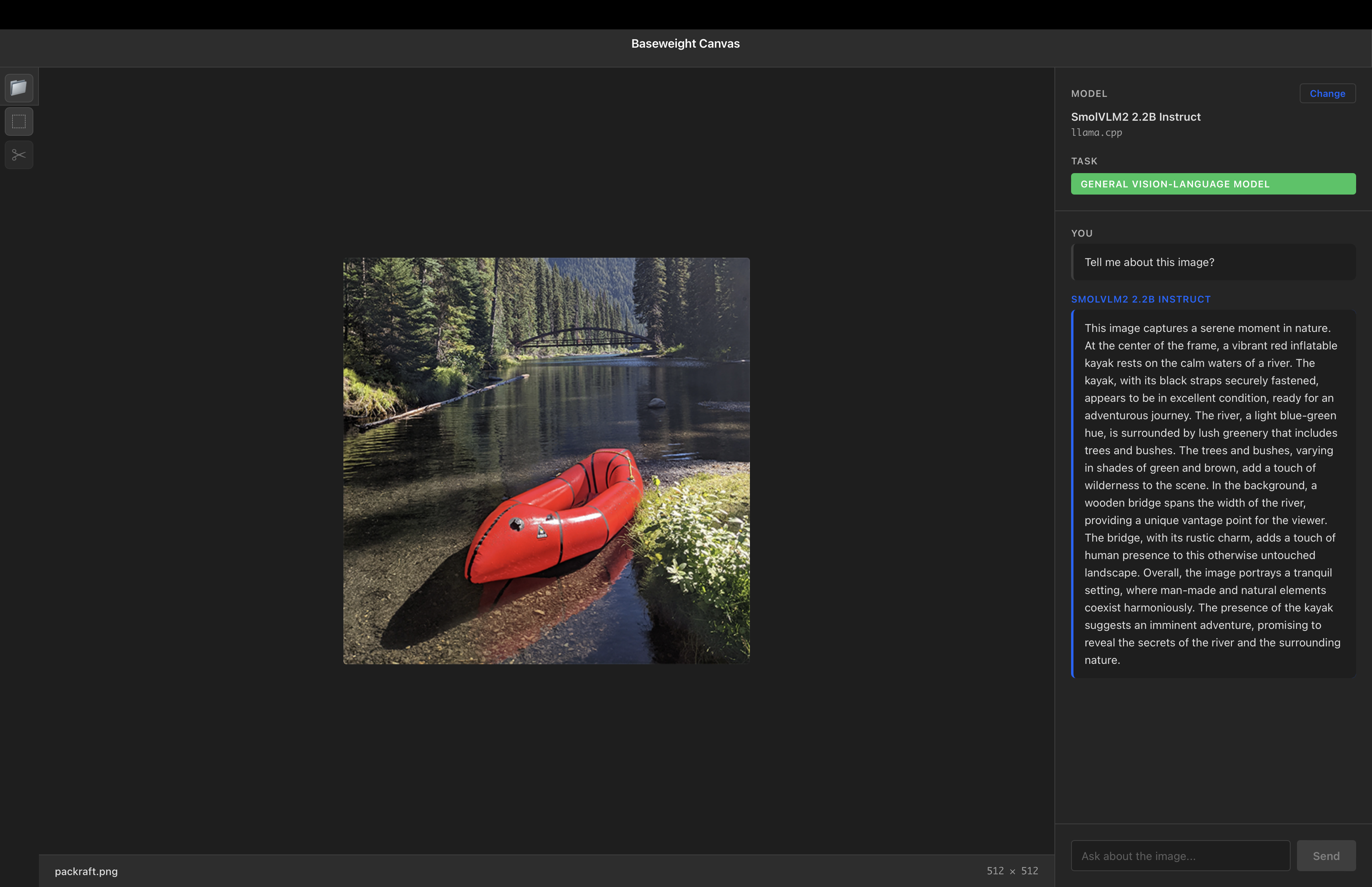
Image Analysis
Talk directly with your images using advanced Visual Language Models. Get insights, descriptions, and answers about visual content.
Audio Processing
Process and interact with audio content seamlessly. Transcription, analysis, and multimodal understanding of audio data.
Multimodal AI
Combine text, images, and audio in natural conversations. Experience AI that understands context across multiple modalities.
Cross-Platform
Native applications for Windows, Linux, and Mac. Consistent experience across all major desktop platforms.
Developer-Focused
Built by developers, for developers. Streamlined interface designed for productivity and workflow integration.
Local Processing
Run models locally on your machine. Your data stays private and secure on your own hardware.
Why Canvas?
Different from Traditional LLM Runners
While tools like ollama focus primarily on text-based language models, Baseweight Canvas is designed from the ground up for multimodal AI.
Traditional LLM Runners
- •Primarily text-focused
- •Vision and audio as afterthoughts
- •Command-line or basic interfaces
- •Limited multimodal workflows
Baseweight Canvas
- ✓Vision and audio first design
- ✓Native multimodal experience
- ✓Intuitive visual interface
- ✓Seamless cross-modal workflows